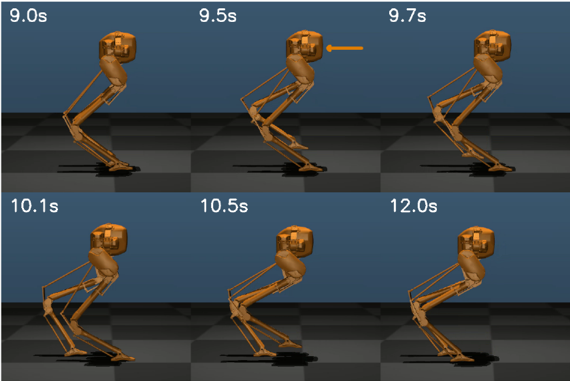
We present a novel model-free reinforcement learning (RL) framework to design feedback control policies for 3D bipedal walking. Existing RL algorithms are often trained in an end-to-end manner or rely on prior knowledge of some reference joint trajectories. Different from these studies, we propose a novel policy structure that appropriately incorporates physical insights gained from the hybrid nature of the walking dynamics and the well-established hybrid zero dynamics approach for 3D bipedal walking. As a result, the overall RL framework has several key advantages, including lightweight network structure, short training time, less dependence on prior knowledge, among others. We demonstrate the effectiveness of the proposed method on Cassie, a challenging 3D bipedal robot. The proposed solution produces stable limit walking cycles that can track various walking speed in different directions. Surprisingly, without specifically trained with disturbances to achieve robustness, it also performs robustly against various adversarial forces applied to the torso towards both the forward and the backward directions. This is a joint effort with Prof. Ayonga Hereid at the Ohio State University. The manuscript can be found here (https://arxiv.org/abs/1910.01748).