“AISPO: Enhancing Depth Reliability for Robotic Manipulation of Non-Lambertian Objects via Affine-Invariant Shape Prior” is accepted by RAL 2026
Reliable depth perception is critical for robotic manipulation, especially for non-Lambertian objects…

Reliable depth perception is critical for robotic manipulation, especially for non-Lambertian objects…
Imitation learning enables robots to acquire complex manipulation skills from demonstrations, but…
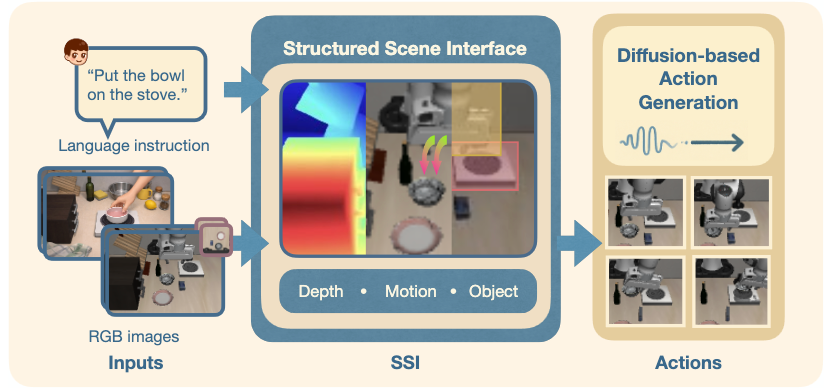
Real-world robotic manipulation demands spatial grounding, task-aware reasoning, and precise control. Learning…
Achieving everyday tasks with humanoid robots requires coordinating stable locomotion with versatile…

Our paper entitled “PolicyFlow: Policy Optimization with Continuous Normalizing Flow in Reinforcement…

Our paper entitled "LIPM-Guided Reinforcement Learning for Stable and Perceptive Locomotion in…
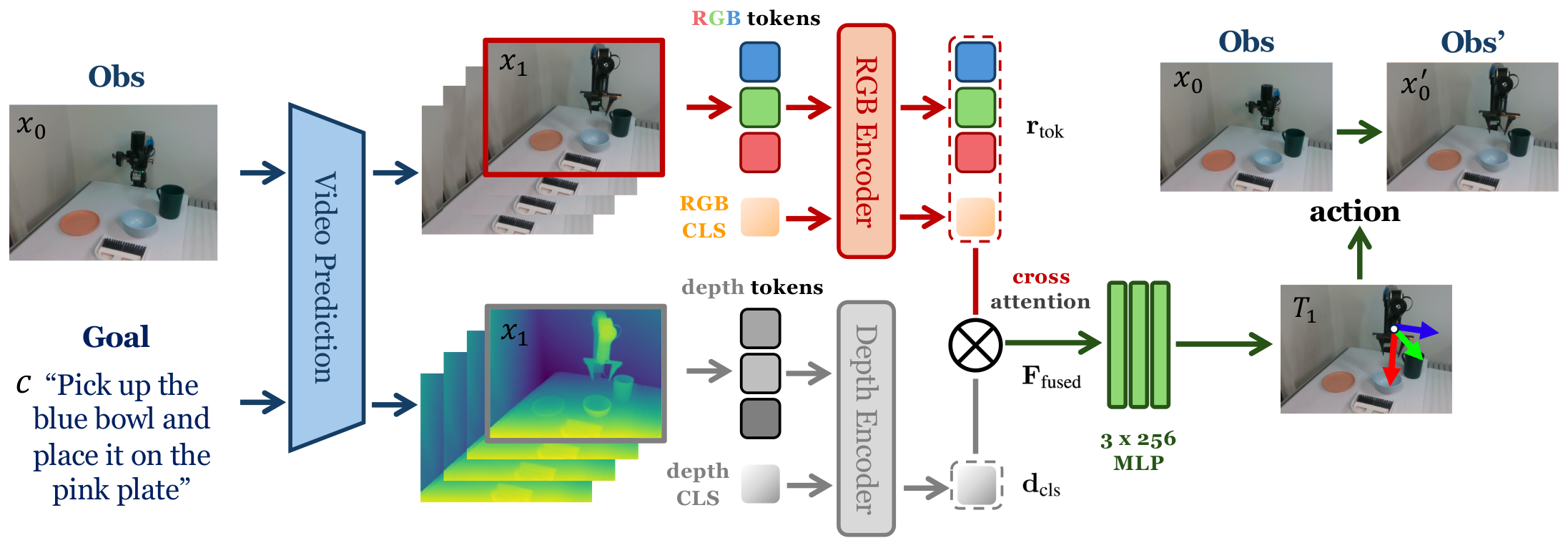
Our paper entitled "Generative Visual Foresight Meets Task-Agnostic Pose Estimation in Robotic…
Our paper entitled "Multi-Loco: Unifying Multi-Embodiment Legged Locomotion via Reinforcement Learning Augmented…

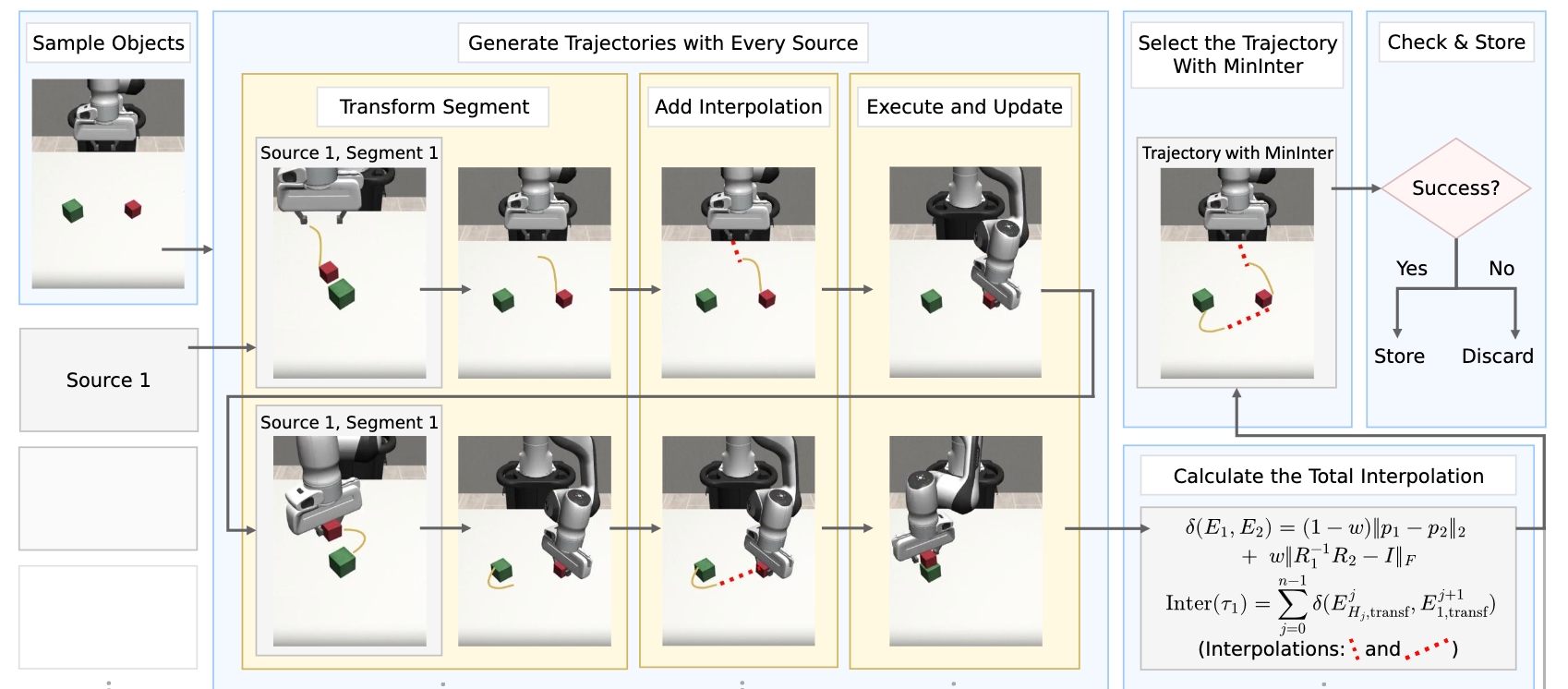
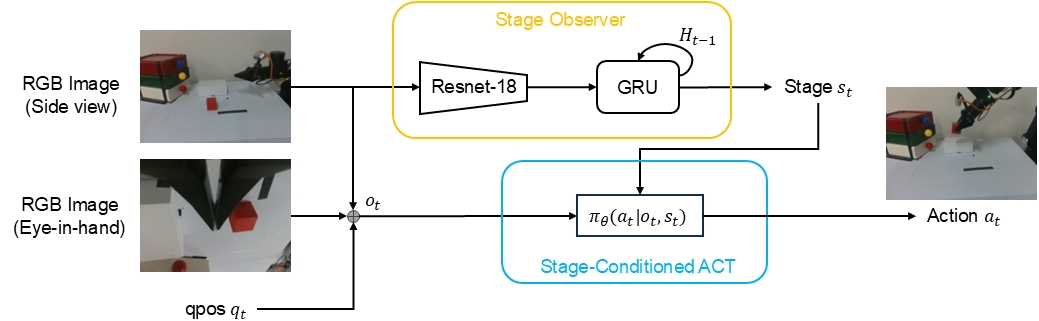
Our paper entitled "SCIL: Stage-Conditioned Imitation Learning for Multi-Stage Manipulation" accepted by…
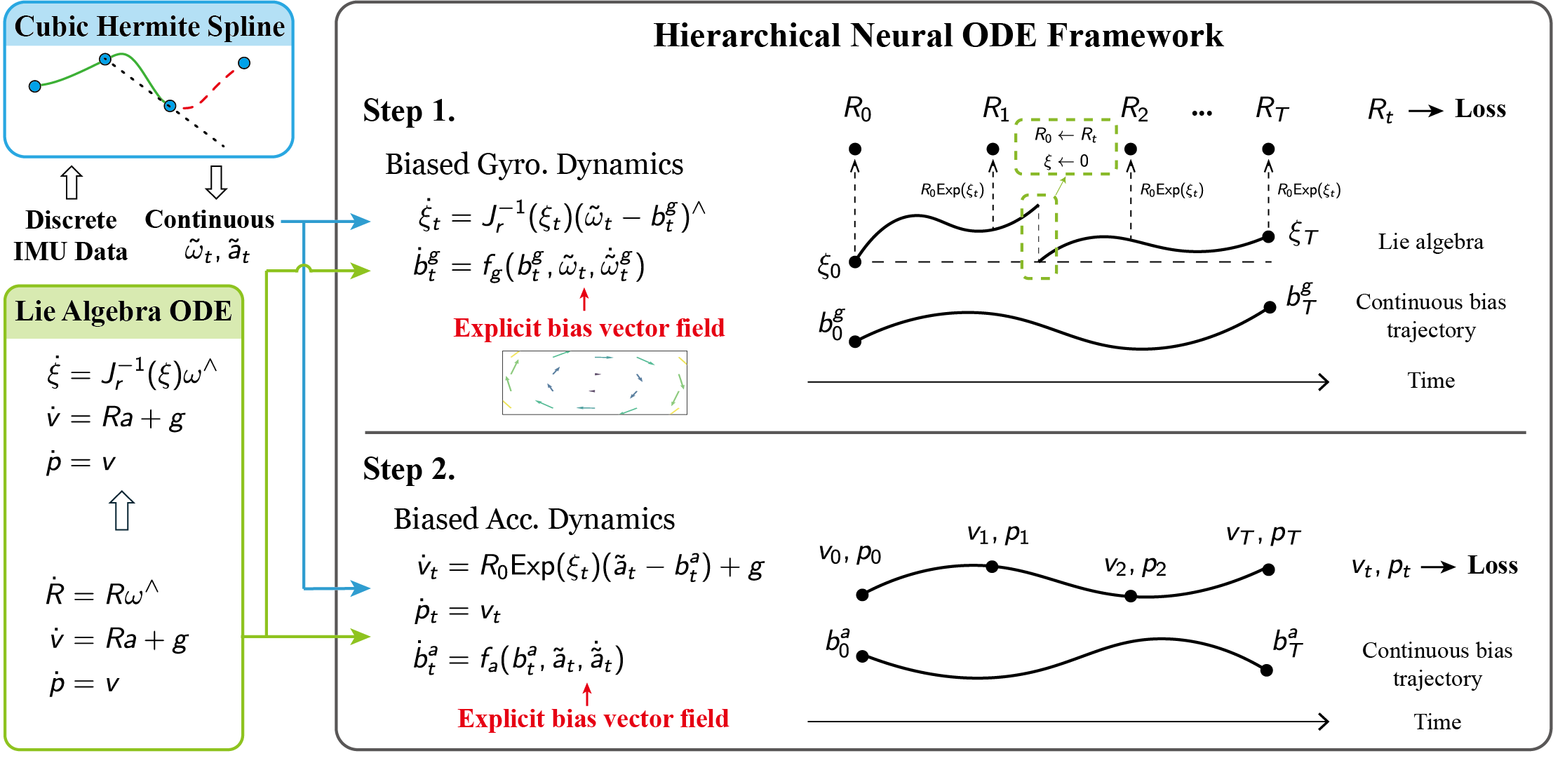
Our paper entitled "Debiasing 6-DOF IMU via Hierarchical Learning of Continuous Bias…
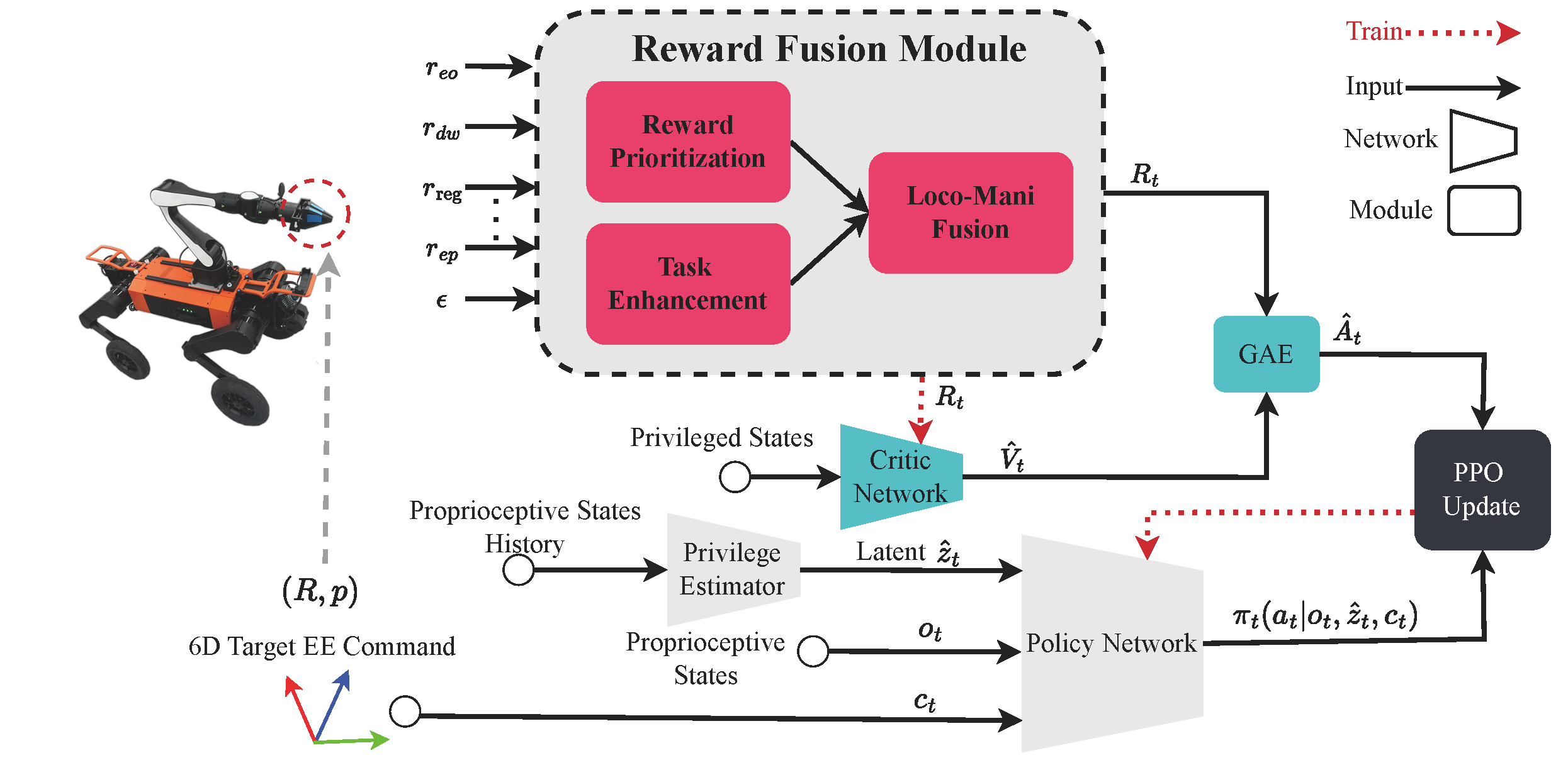
Our paper entitled "Learning Whole-Body Loco-Manipulation for Omni-Directional Task Space Pose Tracking…
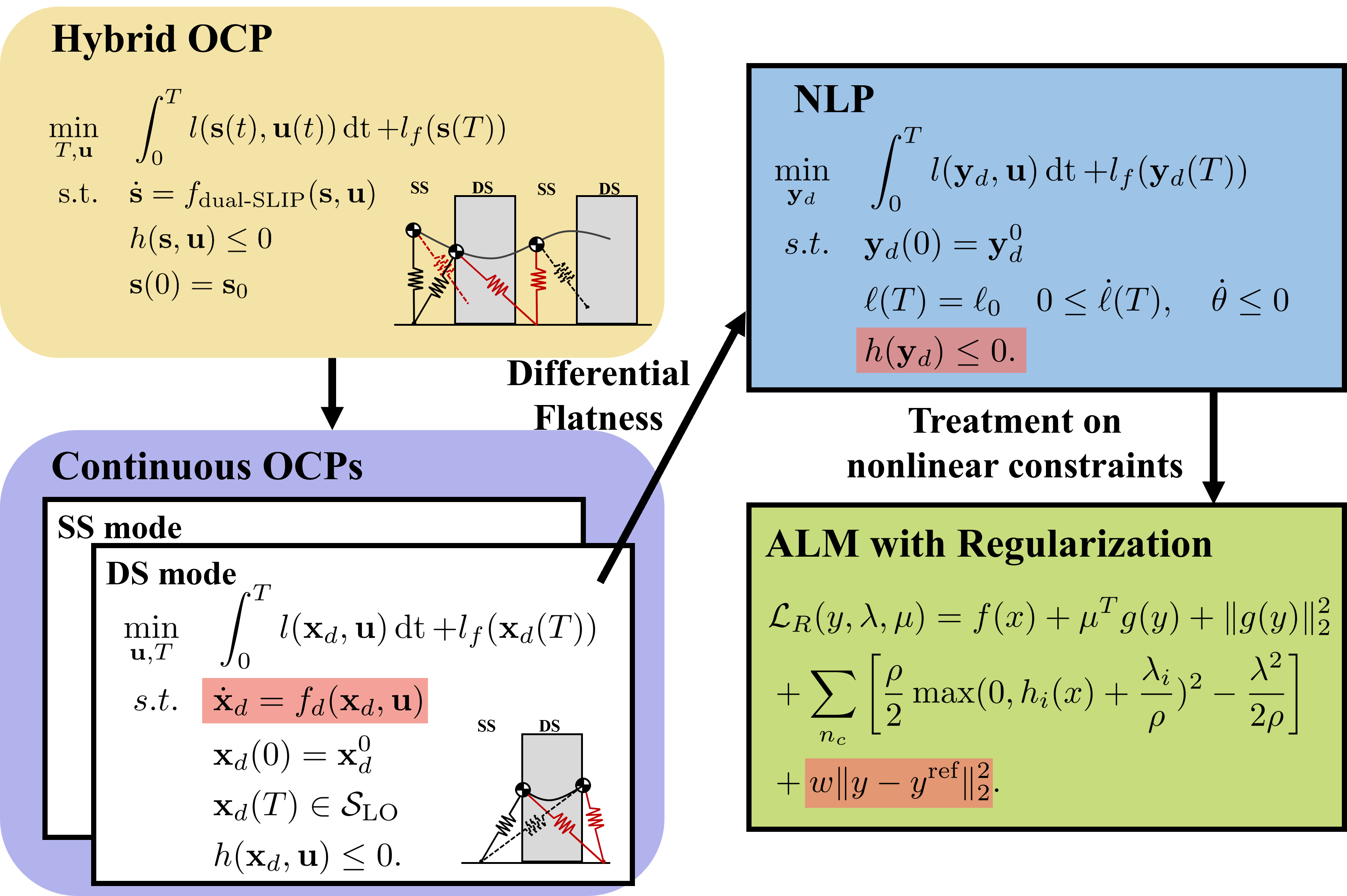
Our paper entitled "An Augmented Lagrangian Perspective on Differential Flatness-Based Control of…
Our paper entitled “Task-Space Riccati Feedback based Whole Body Control for Underactuated…

Our paper entitled “GeoReF: Geometric Alignment Across Shape Variation for Category-level Object…

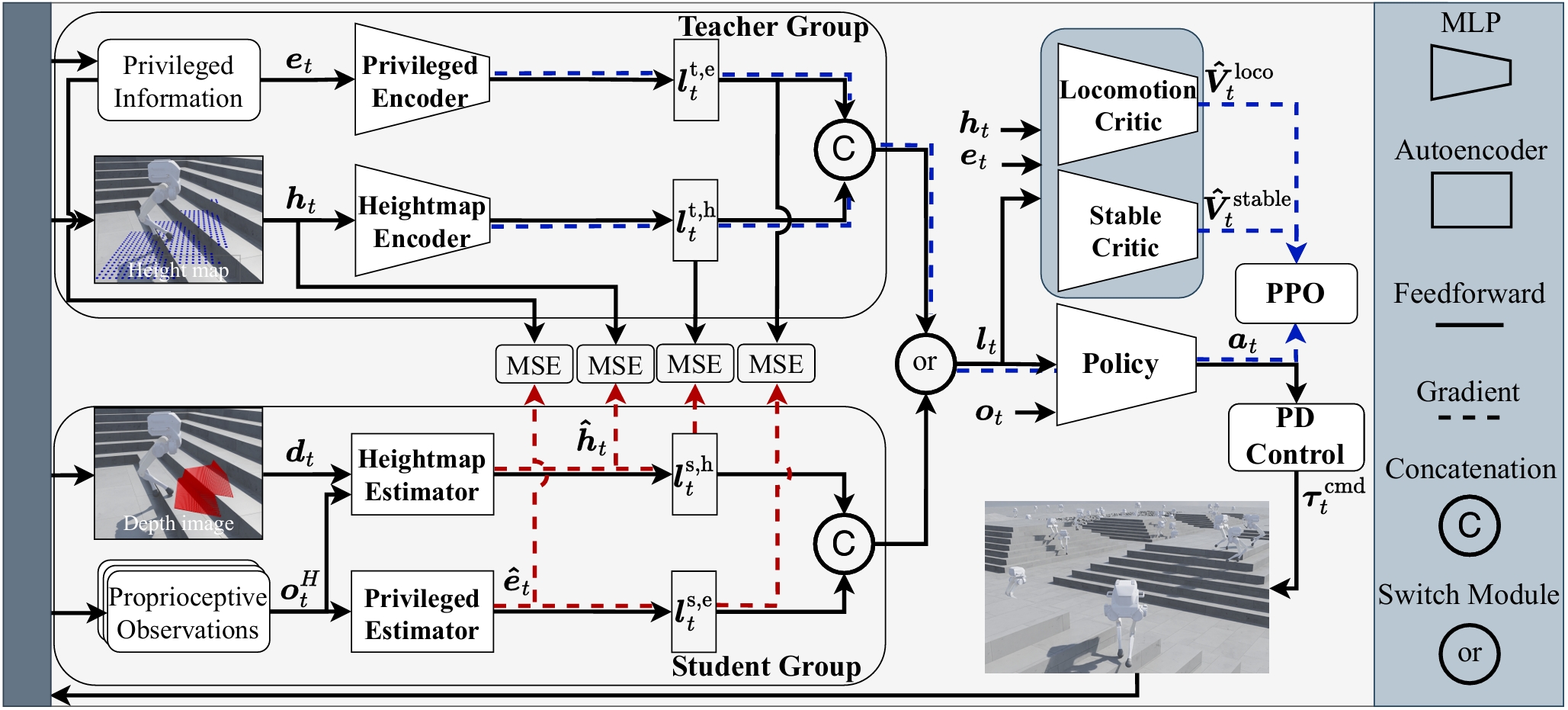
Our paper entitled “CTS: Concurrent Teacher-Student Reinforcement Learning for Legged Locomotion” is…

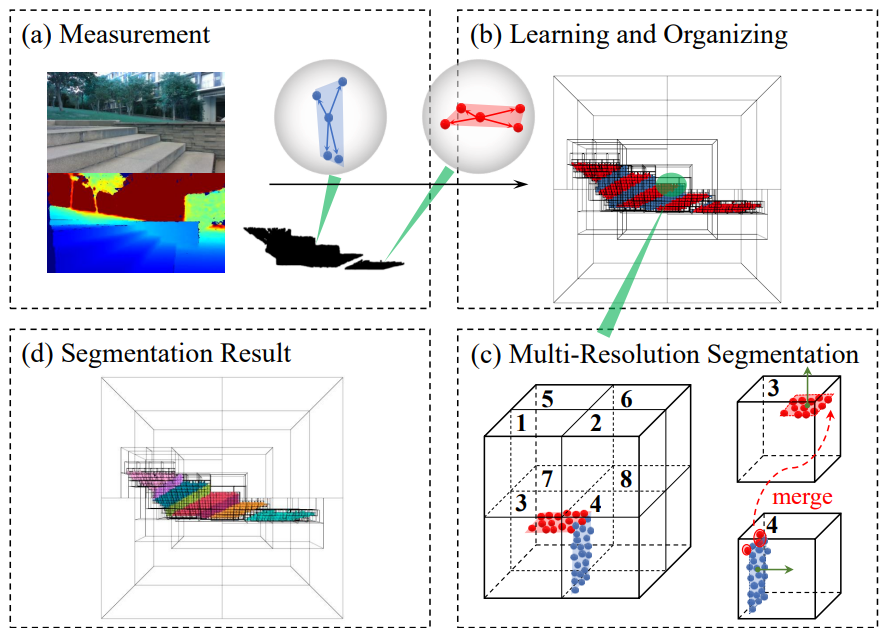
Our paper entitled “Multi-Resolution Planar Region Extraction for Uneven Terrains” is accepted…
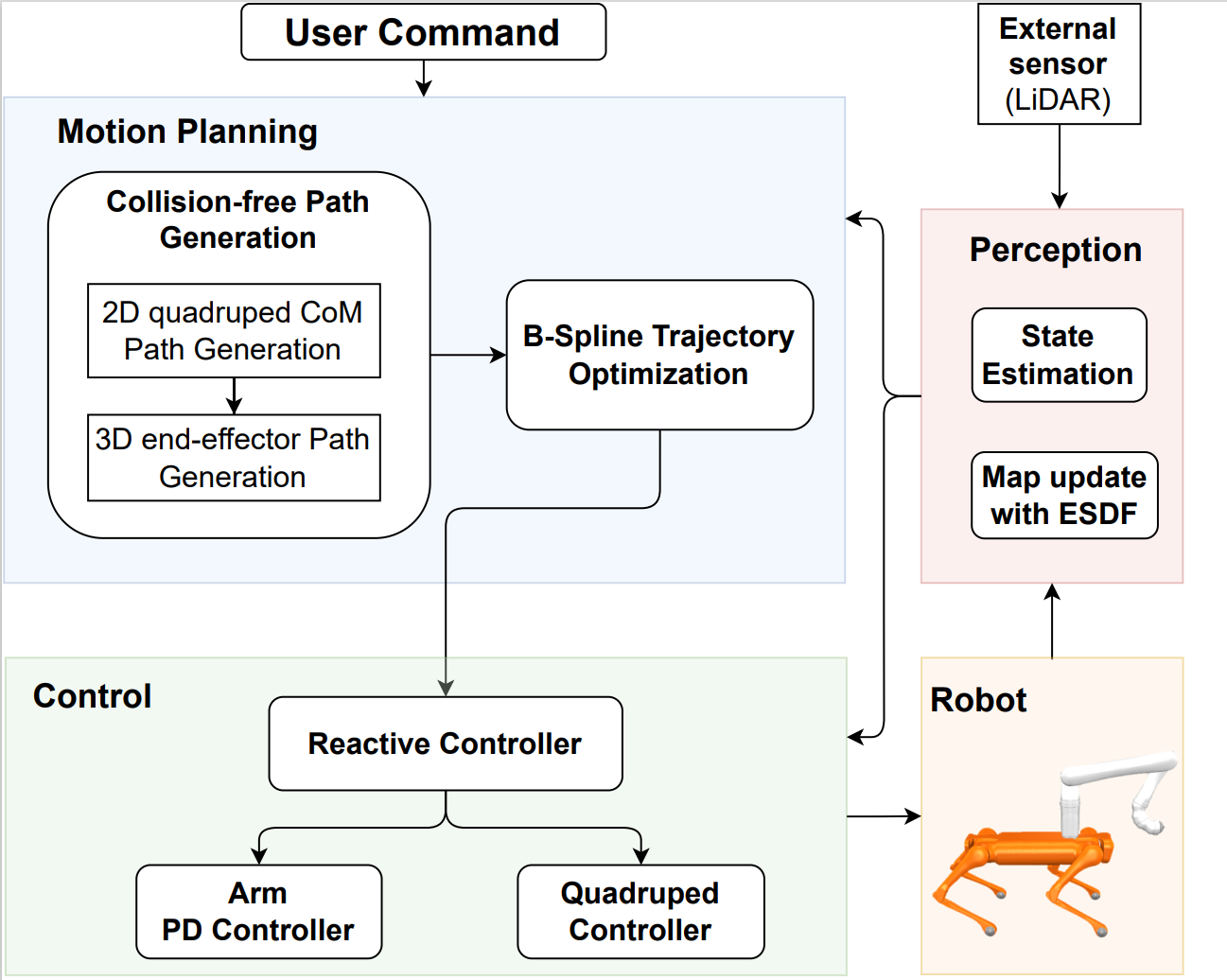
Our paper entitled “Real-Time Collision-Free Motion Planning and Control for MobileManipulation with…
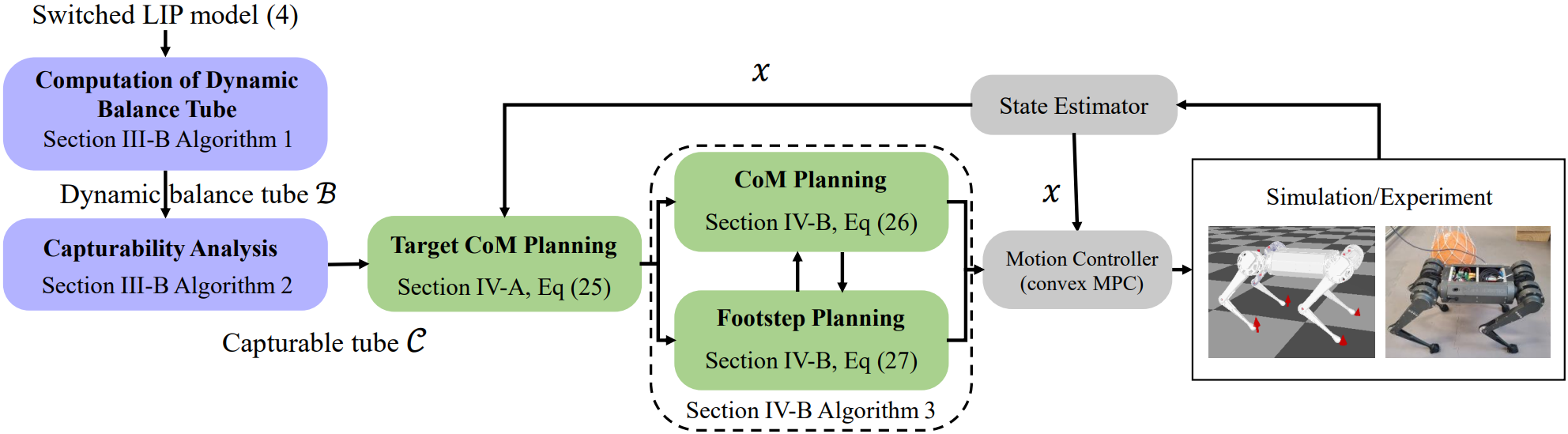
Our paper entitled “Quadruped Capturability and Push Recovery via a Switched-Systems Characterization…
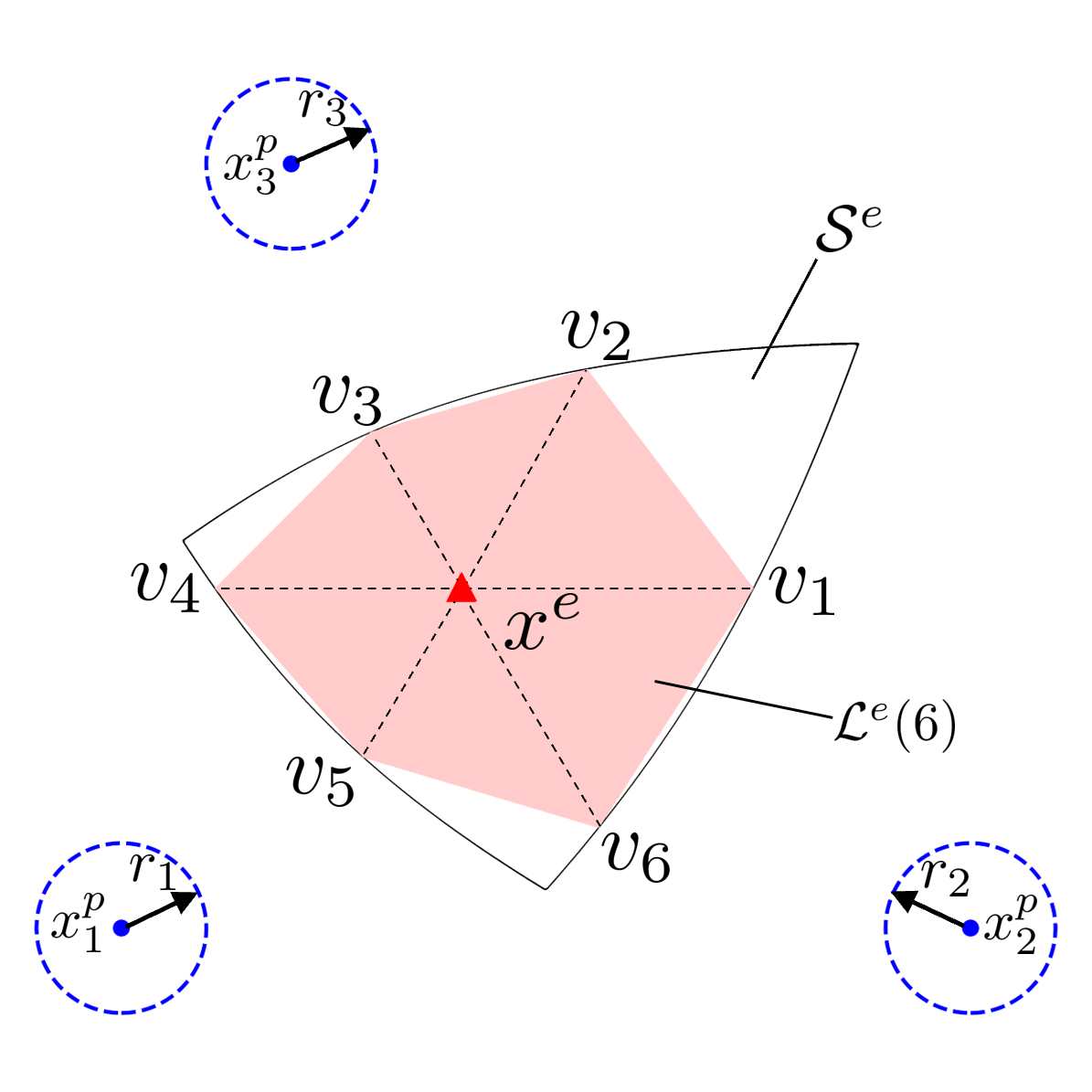
Our paper entitled “Unbounded Cooperative Pursuit Using a Linearized Safe-Reachable Set” is…
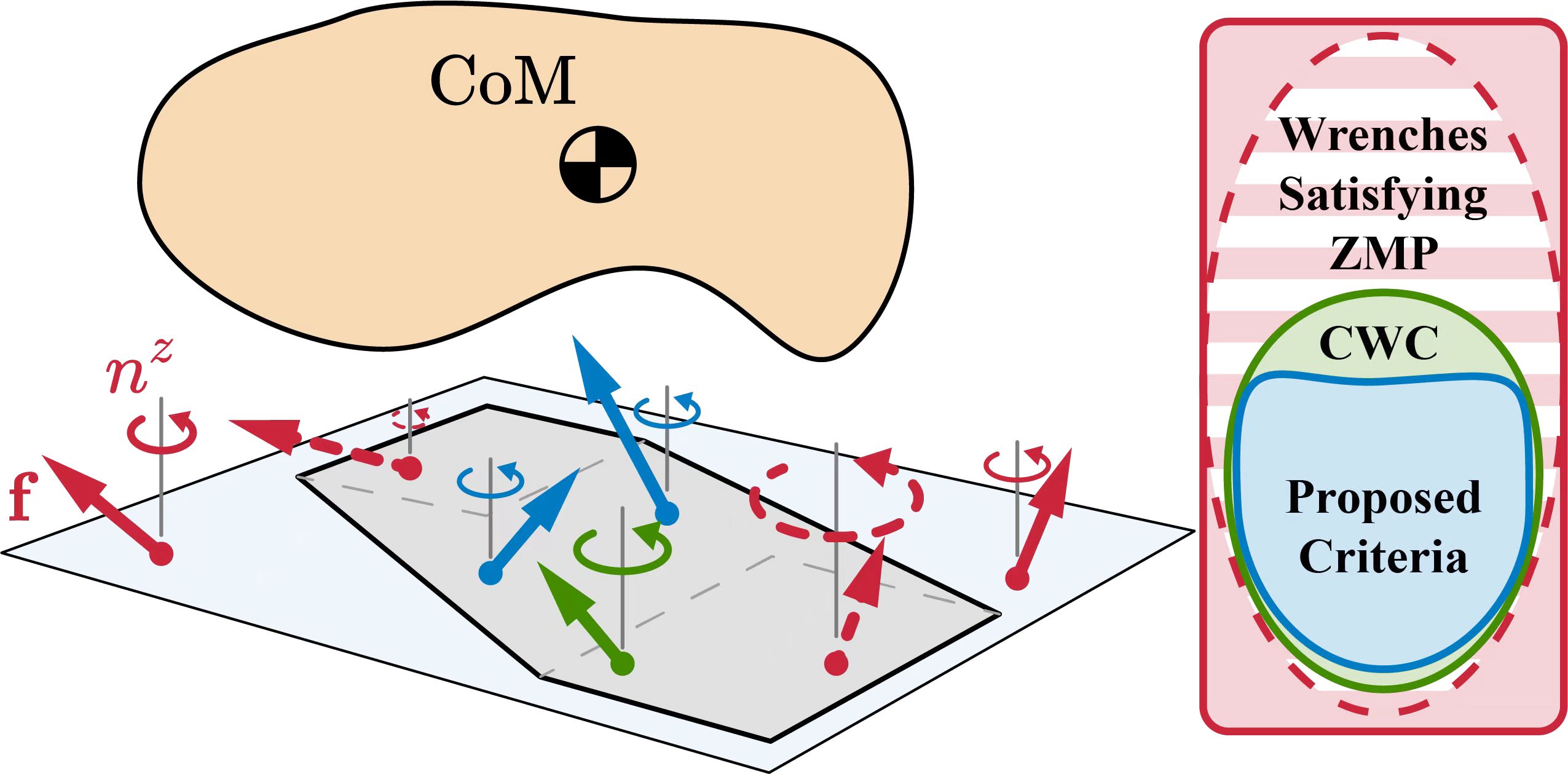
Our paper entitled “A Geometric Sufficient Condition for Contact Wrench Feasibility” is…
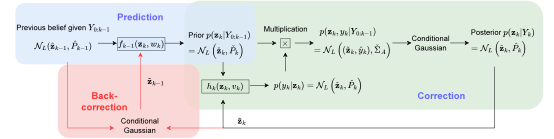
Our paper entitled “A General Iterative Extended Kalman Filter Framework for State…
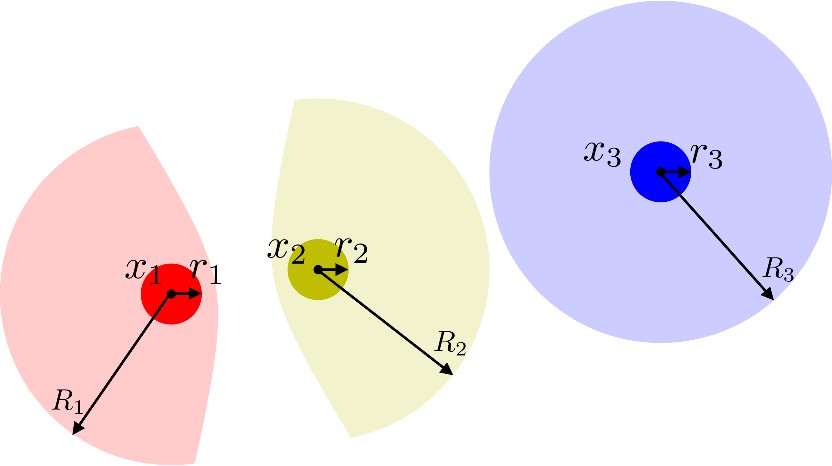
Our paper entitled “Fast Decentralized Multi-Agent Collision Avoidance Based on Safe-Reachable Sets”…
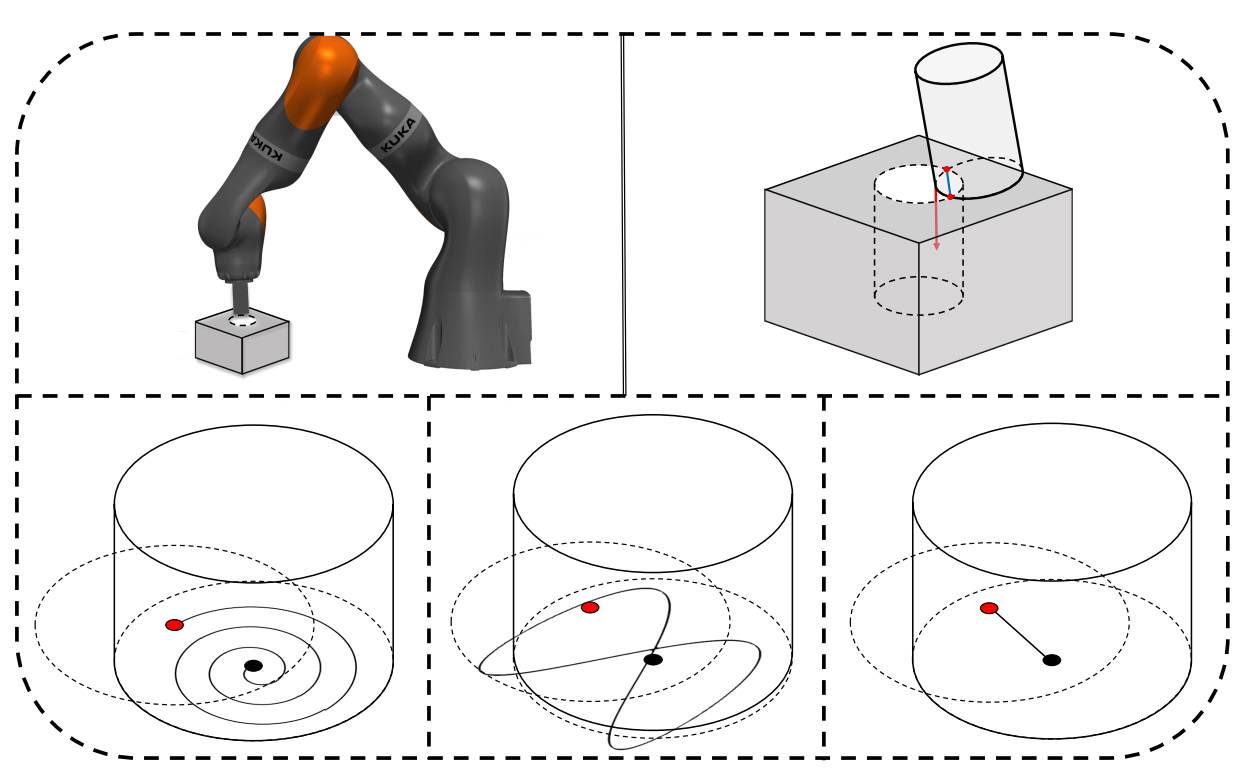
Our paper entitled “POMDP-Guided Active Force-Based Search for Robotic Insertion” is accepted…
Our paper entitled “Reactive Dexterous Ungrasping with Tactile Sensing” is accepted by…
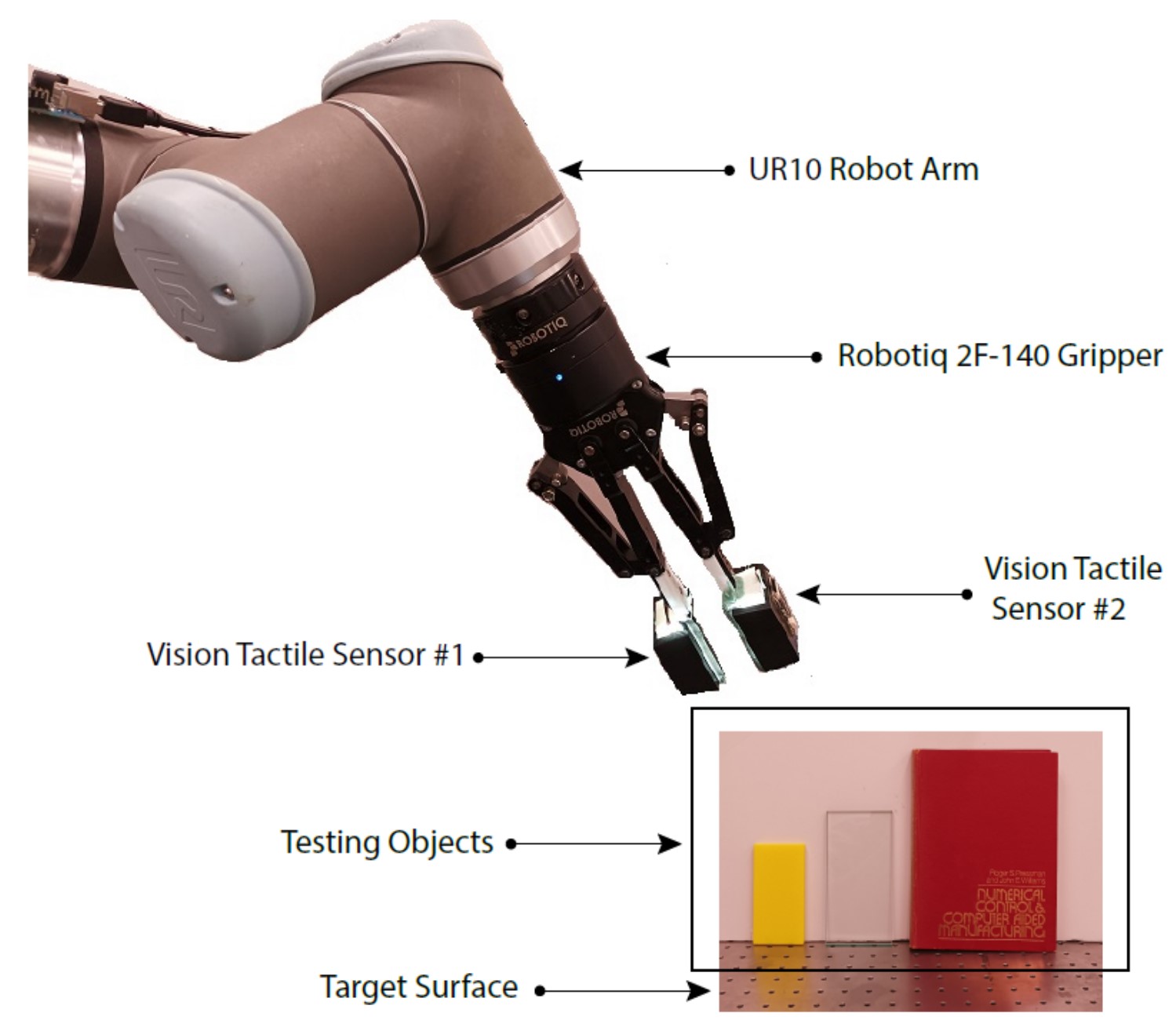
Our paper entitled “A Modular End Effector with Active Rolling Fingertip for…

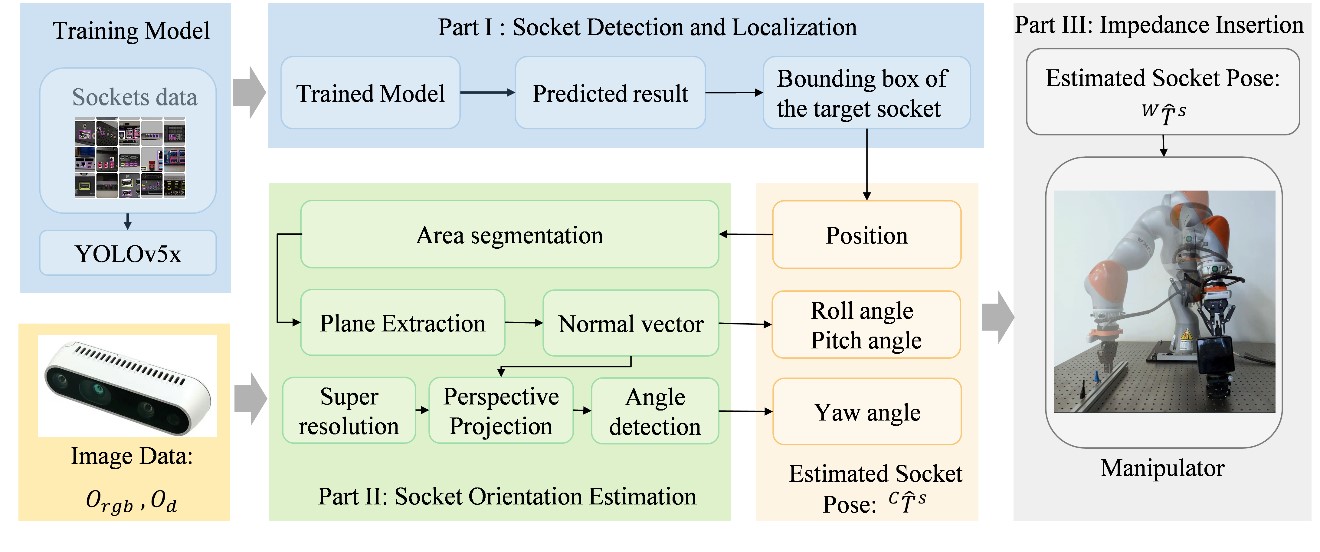
Our paper entitled “Vision-based Six-Dimensional Peg-in-Hole for Practical Connector Insertion” is accepted…
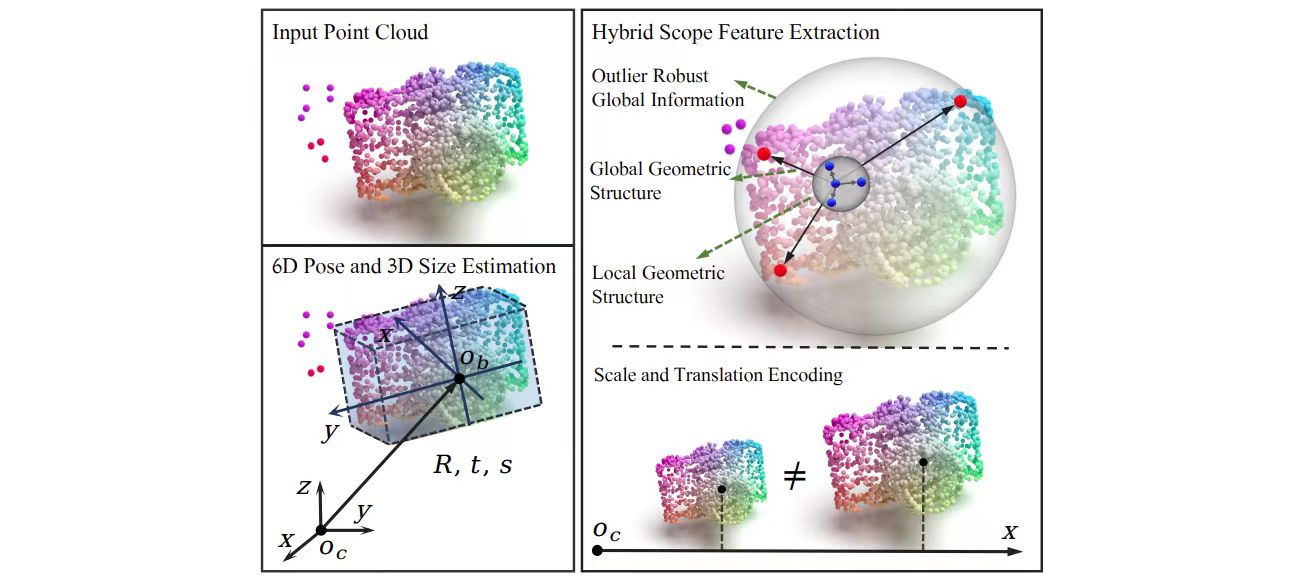
Our paper entitled “HS-Pose: Hybrid Scope Feature Extraction for Category-level Object Pose…
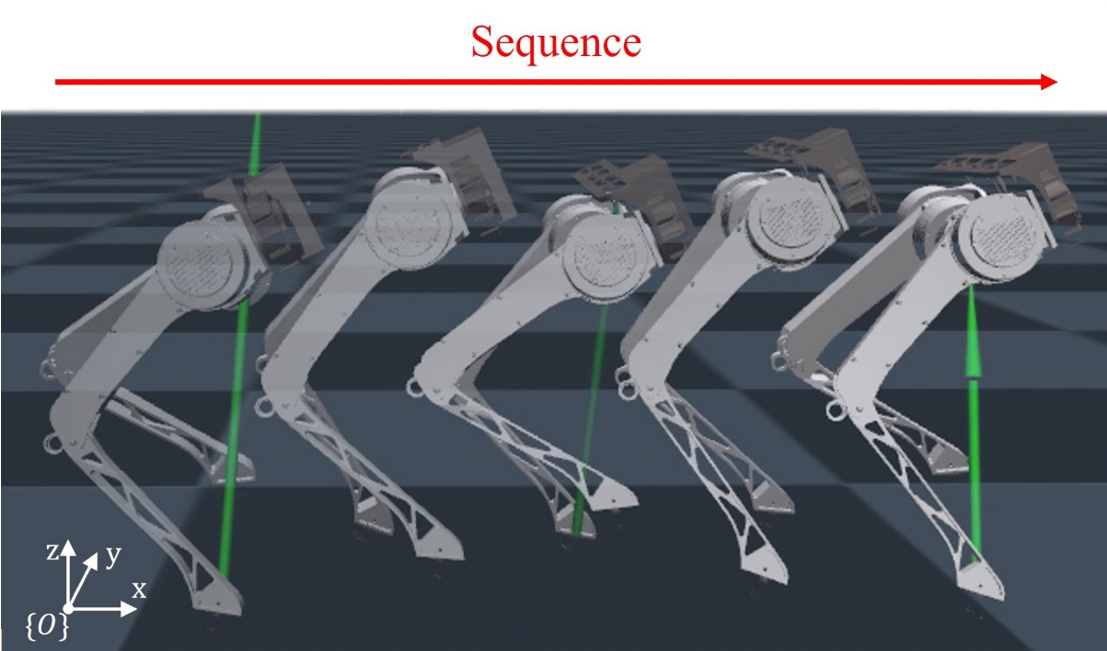
Our paper entitled “Improved Task Space Locomotion Controller for a Quadruped Robot…

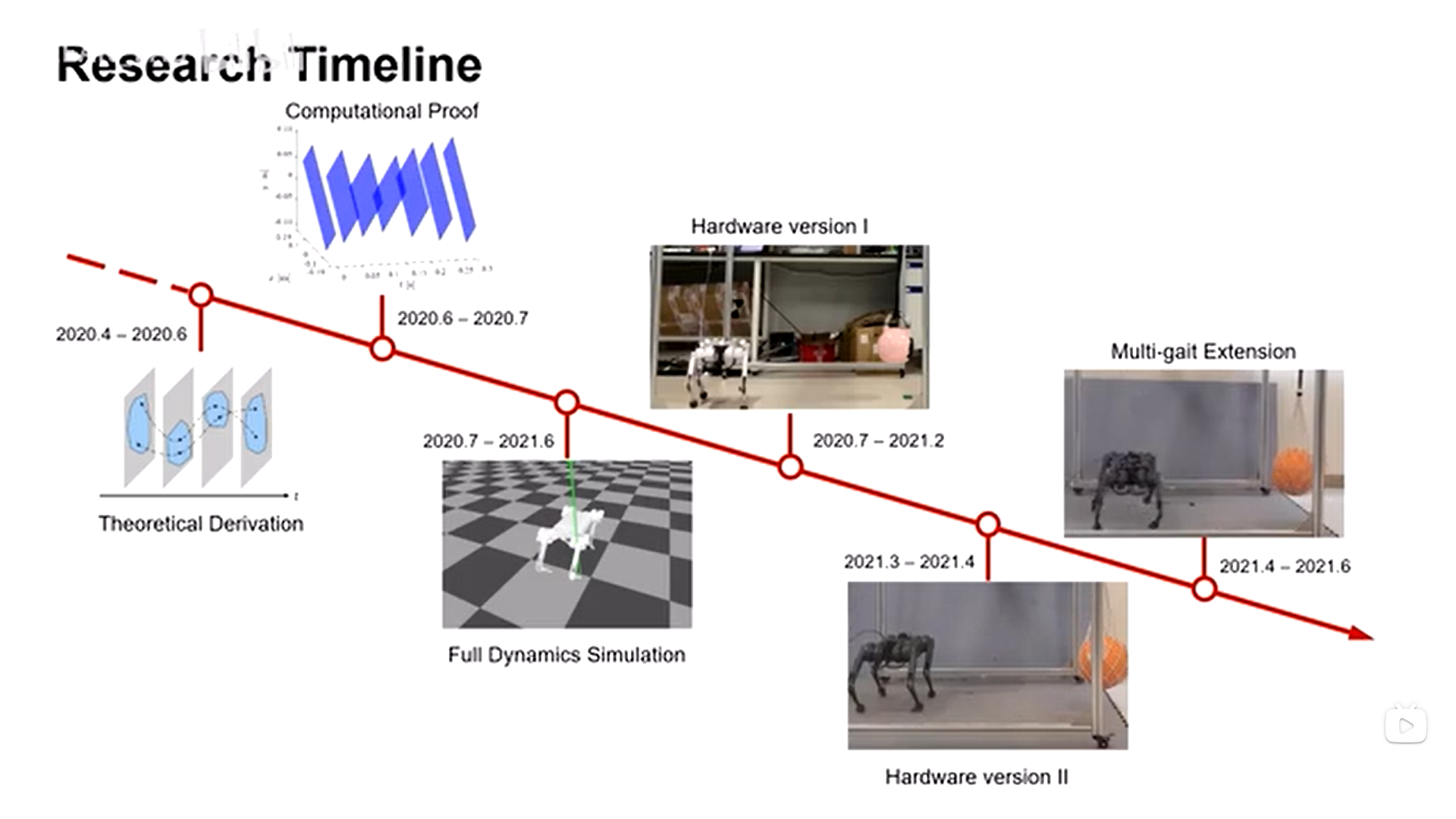
Our paper entitled “Three-Dimensional Dynamic Running with a Point-Foot Biped based on…
http://www.wzhanglab.site/wp-content/uploads/2022/09/BIPED-II-PRESSED.mp4

http://www.wzhanglab.site/wp-content/uploads/2022/09/SUSTech-3D-Point-Foot-Biped-pressed.mp4

Our paper entitled “TP-AE: Temporally Primed 6D Object Pose Tracking with Auto-Encoders”…

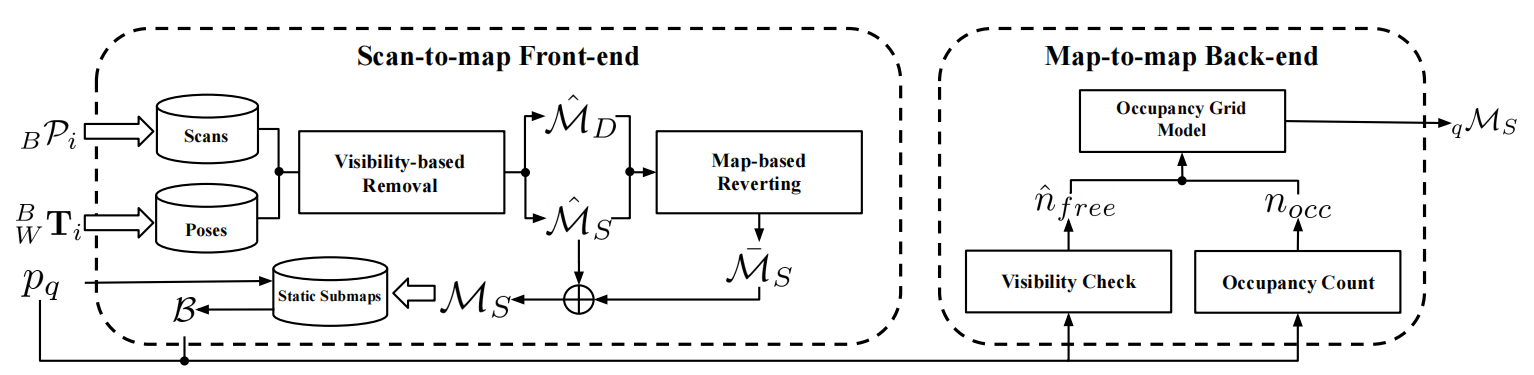
Our paper entitled "DynamicFilter: an Online Dynamic Objects Removal Framework for Highly…
This paper studies capturability and push recovery for quadrupedal locomotion. Despite the…
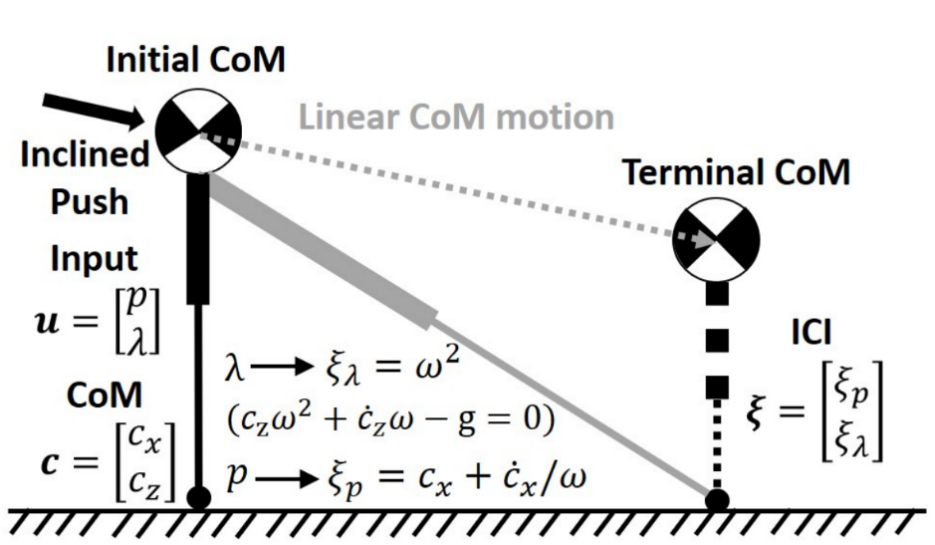
Our paper entitled "Instantaneous Capture Input for Balancing the Variable Height Inverted Pendulum" is accepted…
Our paper entitled "Force-feedback based Whole-body Stabilizer for Position-Controlled Humanoid Robots" is accepted…
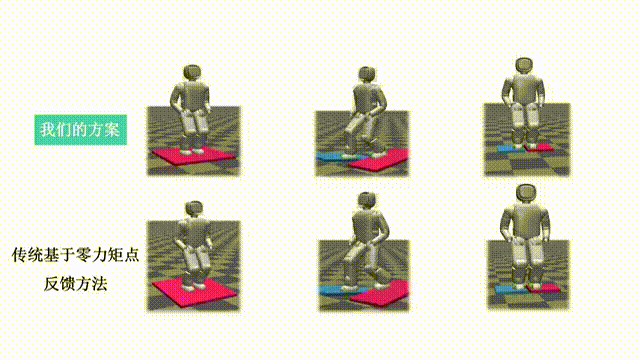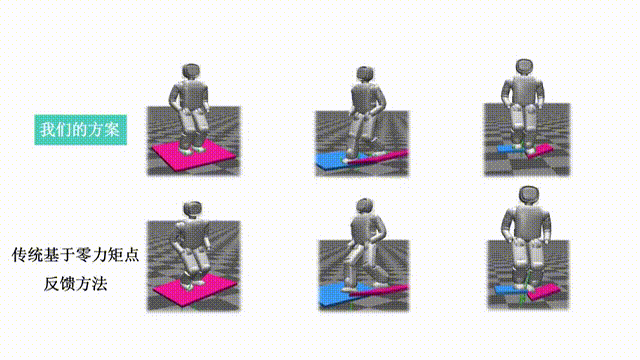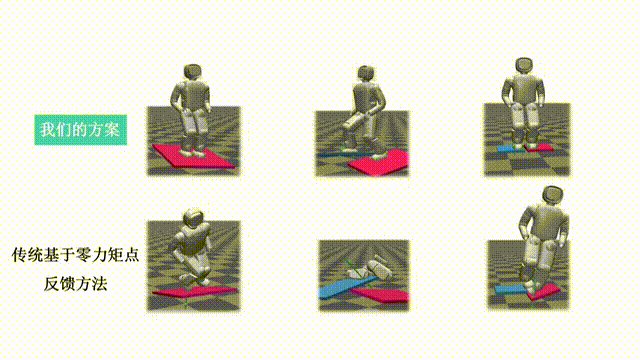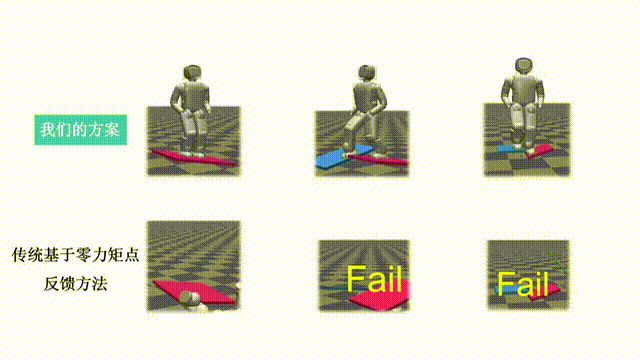
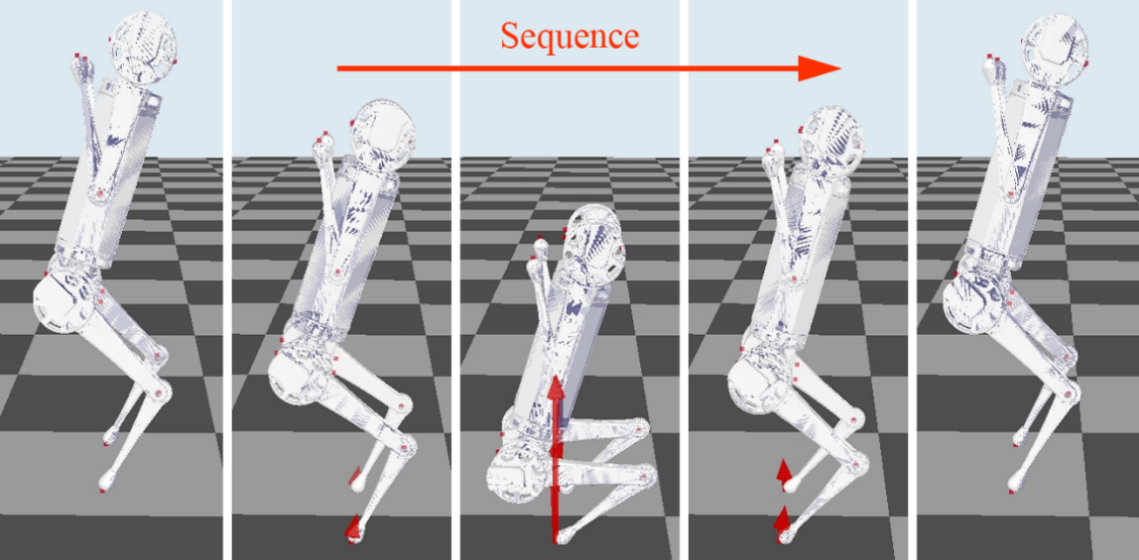
Our paper entitled "Quadruped Robot Hopping on Two Legs" is accepted by IROS 2021. This paper…
Our paper entitled “Encirclement Guaranteed Cooperative Pursuit with Robust Model Predictive Control” is accepted by IROS…
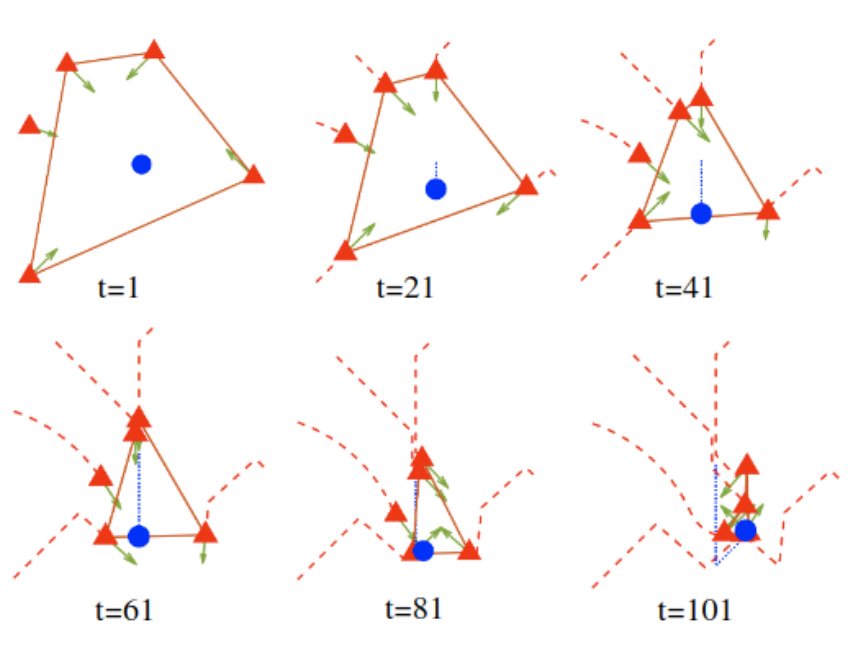
Our paper entitled “Robust Feedback Motion Policy Design Using Reinforcement Learning on a 3D…

Our paper entitled “Non-asymptotic Convergence of Adam-type Reinforcement Learning Algorithms under Markovian…

Our paper entitled “Finite-Time Analysis for Double Q-learning” has been accepted for…

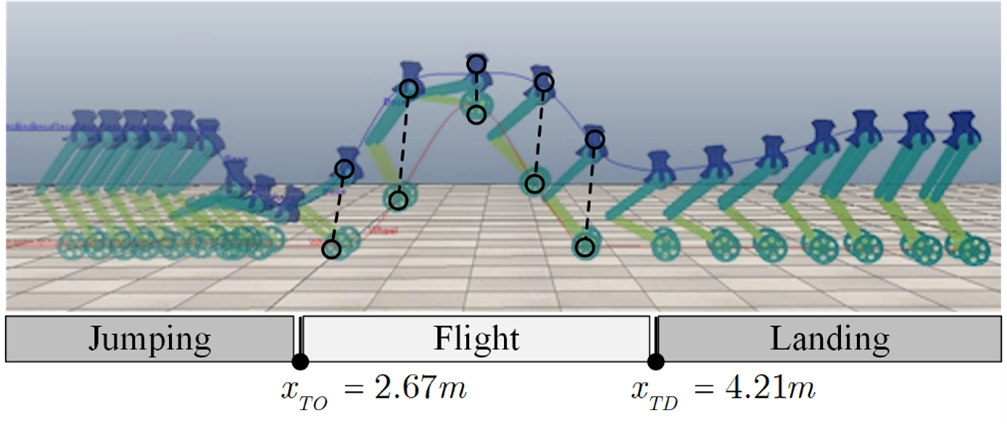
Our paper entitled “Underactuated Motion Planning and Control for Jumping with Wheeled-Bipedal…
We propose a novel perception-aware planning and control scheme for quadruepdal stair…

Our lab recently developed a new push recovery strategy for quadruped. Most…

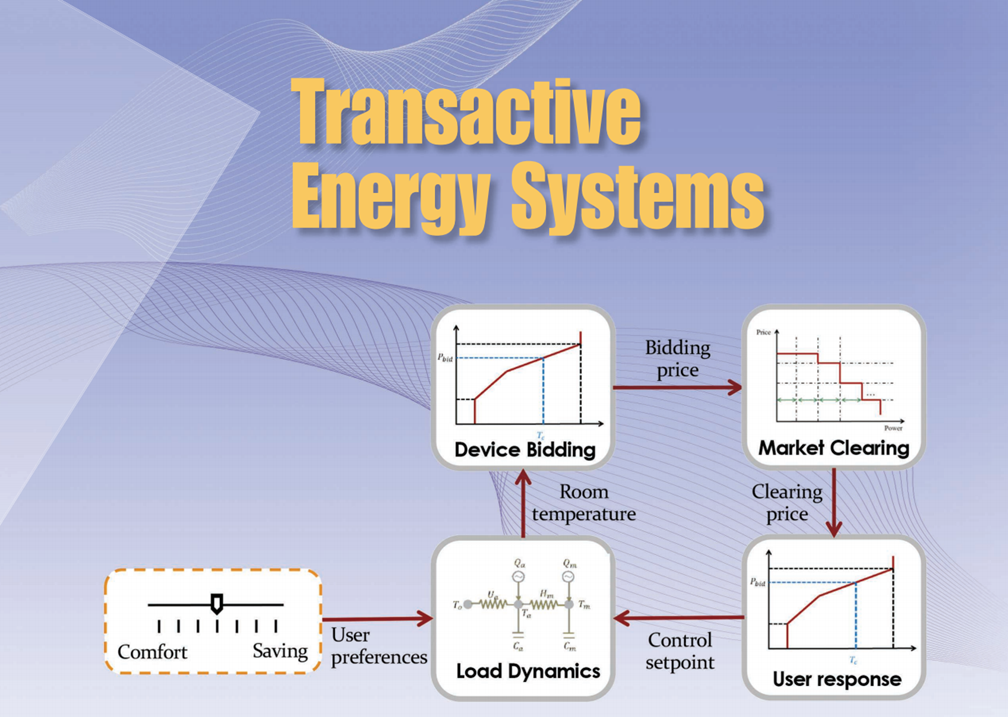
Our paper entitled “Transactive energy systems: The market-based coordination of distributed energy…
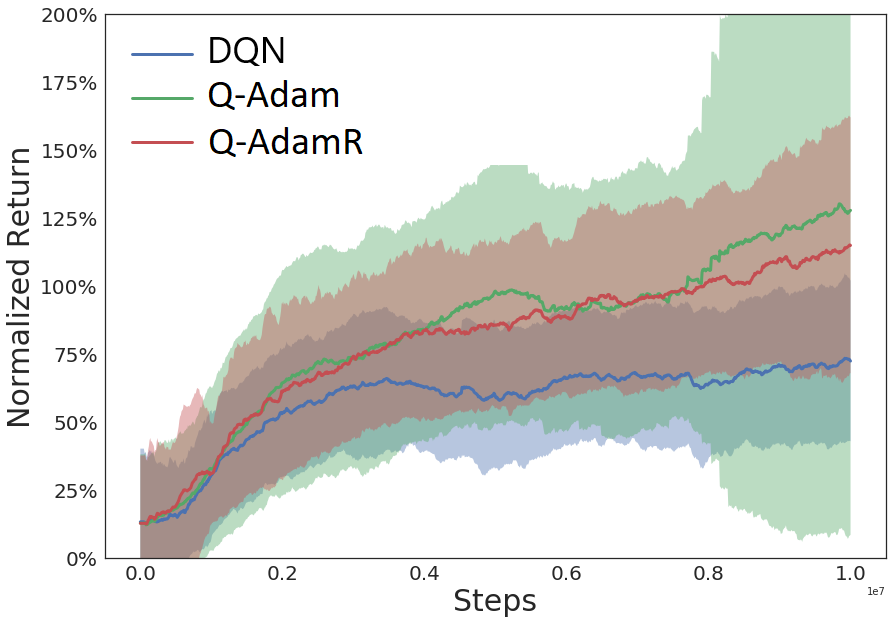
Our new paper entitled, “Analysis of Q-learning with Adaptation and Momentum Restart…
To enable quadruped robot to autonomously navigate through complex environment with dynamic…

Our new paper entitled “Analytical convergence regions of accelerated gradient descent in…
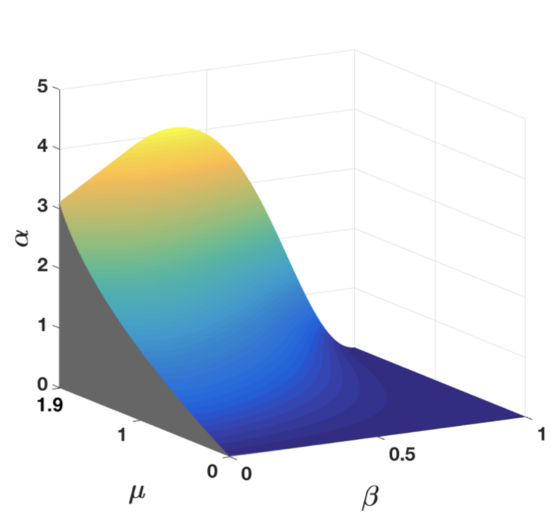
Our new paper entitled “Optimal Control Inspired Q-Learning for Switched Linear Systems”…
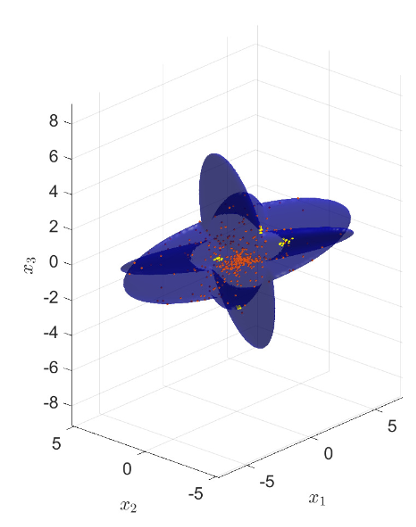
Our new paper entitled “Connections between mean-field game and social welfare optimization”…
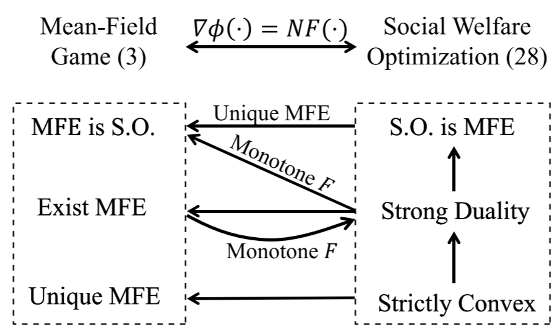
Our new paper entitled “Optimal Control of a Differentially Flat 2D Spring-Loaded…
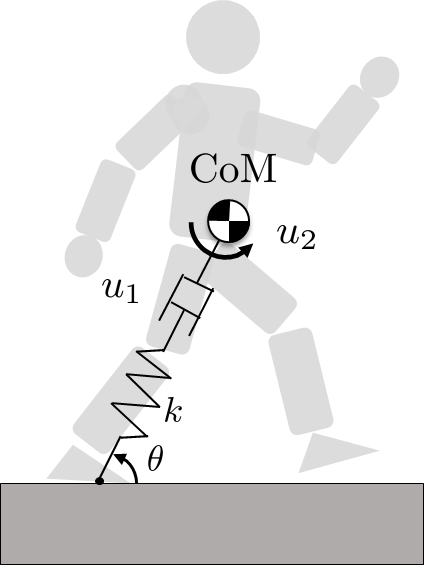
Take a look at our in-house built quadruped robot with customized motor…

We present a novel model-free reinforcement learning (RL) framework to design feedback…
